Perceptron#
import numpy as np
import matplotlib.pyplot as plt
Linear Classification Problem#
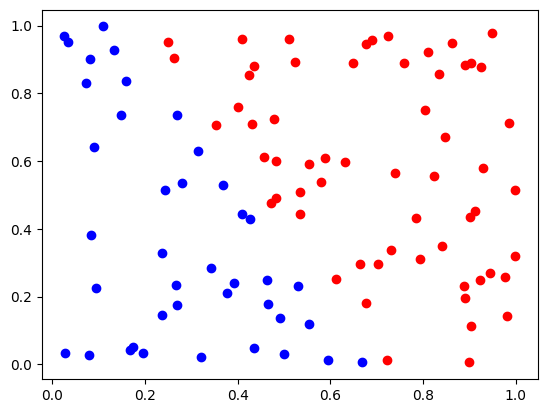
Let’s start by generating a simple linear classification problem. That is, a problem in which the optimal decision boundary is known to be linear. We’re also generating a problem in which the samples are perfectly linearly separable. This is the exception rather than the rule.
data = np.random.random_sample((100,2))
labels = (data[:,0]*0.7+data[:,1]*0.4>0.5)
d0 = data[labels==False]
d1 = data[labels]
plt.plot(d0[:,0],d0[:,1],"bo")
plt.plot(d1[:,0],d1[:,1],"ro")
print(len(d0),len(d1))
40 60
We can visually read off the equation for the decision boundary. It should run from (0.15,1.0) to about (0.7,0.0).
d0 = data[labels==False]
d1 = data[labels]
plt.xlim((0,1))
plt.ylim((0,1))
plt.plot(d0[:,0],d0[:,1],"bo")
plt.plot(d1[:,0],d1[:,1],"ro")
plt.plot([0.15,0.72],[1.0,0.0],"g") # guess
[<matplotlib.lines.Line2D at 0x7f4498285d10>]
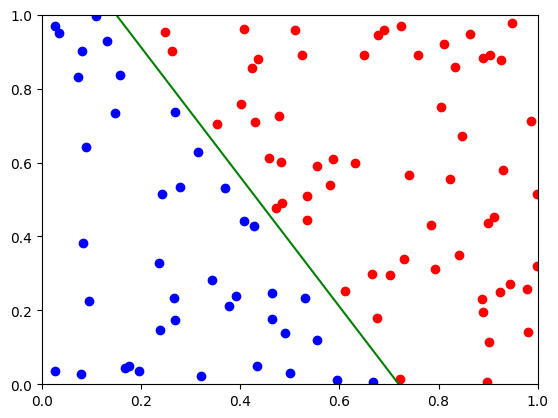
Note that these decision boundaries are linear, by construction.
How do we find these decision boundaries automatically?
(augmented vectors)
To simplify computations, we would like to use homogeneous coordinates.
A linear decision boundary is given by a formula of the form:
We can write this as
With this, we classify as class 0:
and as class 1:
(augmented vectors)
However, it turns out to be inconvenient to have the \(d\) in all our equations; we therefore turn this inhomogeneous problem into a homogeneous one by transforming the vectors.
Now we can write for our decision problem:
and
Therefore, for any inhomogeneous linear decision problem, we can construct an equivalent homogeneous one by simply adding a column of 1’s to the data vector
The Perceptron Learning Algorithm#
(sample correction)
We want \(a \cdot x \gt 1\) for all samples in class 1. Now, assume that this isn’t working for some sample \(x\), \(a \cdot x \leq 0\) even though it should be \(\gt 0\). How do we fix that?
Actuall, the solution is fairly simple:
When \(a \cdot x \leq 0\) when it should be \(\gt 0\), we add “a little bit of \(x\)” to \(a\).
That is, we update \(a \rightarrow a + \epsilon x\).
Then, next time, \((a + \epsilon x) \cdot x = a \cdot x + \epsilon ||x||^2 > a \cdot x\).
For the other case, we subtract a little bit of \(x\).
(flipping class 0 to class 1)
Notice that the two cases are symmetrical.
Instead of considering two classes, we can simplify the problem further by flipping the sign of \(x\) for all the samples in class \(0\).
Then, we require for all samples in the transformed problem that \(a \cdot x \gt 0\).
(Remember that we have also augmented the data vector).
(perceptron learning algorithm)
So, the perceptron learning algorithm is:
given input samples \(\\{x_1,...,x_N\\} \subseteq R^n\) and corresponding classifications \(\\{c_1,...,c_N\\} \subseteq \\{0,1\\}\)
replace all the \(x_i\) with augmented vectors \(x_i \rightarrow (1,x_i)\)
for every sample for which \(c_i=0\), negate the corresponding \(x_i\), that is \(x_i \rightarrow -x_i\)
pick a random starting vector \(a\)
repeatedly iterate through the training samples \(x_i\)
if \(a \cdot x_i > 0\) then continue
otherwise update \(a\) according to \(a \rightarrow a + \epsilon x_i\)
stop if there are no more updates
Actually, it turns out that we can just use \(\epsilon = 1\).
augmented = np.concatenate([np.ones((100,1)),data],axis=1)
flipped = augmented.copy()
flipped[labels==False] = -flipped[labels==False]
a = np.random.random_sample((3))
for epoch in range(100):
nchanged = 0
for i in range(len(flipped)):
if np.dot(a, flipped[i]) > 0:
continue
a += flipped[i]
nchanged += 1
if nchanged == 0:
break
d,a0,a1 = a
print(d, a0, a1)
-1.6860930432966623 2.372002185150982 1.2726293815117422
The linear equation is now:
For \(x=0\):
For \(y=0\):
d0 = data[labels==False]
d1 = data[labels]
plt.xlim((0,1))
plt.ylim((0,1))
plt.plot(d0[:,0],d0[:,1],"bo")
plt.plot(d1[:,0],d1[:,1],"ro")
plt.plot([0,-d/a0],[-d/a1,0],"g")
print(len(d0),len(d1))
40 60
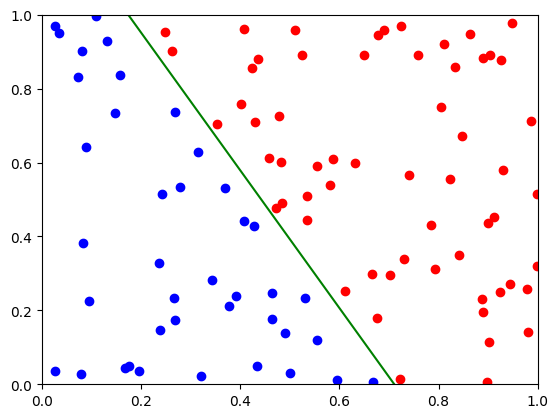
That has worked rather well, but it leaves open a number of questions:
Is the algorithm guaranteed to stop?
How do we deal with more than two classes?
What is the error rate?
How does it relate to the c.c.d. \(p(x|c)\)?
What happens when the data isn’t linearly separable?
It’s fairly easy to show that the algorithm converges if the data is linearly separable.
The Perceptron Criterion Function#
(criterion functions)
In the perceptron learning algorithm, we made a change to the weight vector every time a sample was misclassified.
In essence, we have been trying to minimize the number of misclassified samples
We call the number of misclassified samples \(J(w) = \hbox{\# misclassified samples}\) a criterion function.
Discriminative learning algorithms are frequently expressed in terms of optimization of criterion functions.
(optimization algorithms)
The number of misclassified samples is an inconvenient criterion function because it is piecewise constant (it is a collection of step functions), so its gradient is either zero or infinity.
Most numerical optimization algorithms use gradients in some form.
(perceptron criterion function)
A better function is to sum up the total amount by which samples on the wrong side of the decision boundary are misclassified.
This is zero when the data is separated, but positive if any samples are misclassified.
In formulas:
where
(gradient descent optimization)
We can optimize this function by gradient descent. That is, we iteratively update the weight vector \(w\) by adding a small multiple of the negative of the gradient \(\nabla J_p(w)\) to it. What is the gradient?
Therefore, our update rule becomes:
(stochastic vs batch gradient descent)
This is a batch update rule; that is, we add up all the gradients for each misclassified samples, and only then update the total weight vector. That is inefficient and turns out to be unnecessary in this case anyway.
A stochastic gradient descent rule updates after every misclassified sample via
In the case of perceptron learning, this is also called the single sample correction algorithm.
Proof of Convergence#
Let’s consider a particularly simple case for the single sample correction perceptron learning algorithm: the case where \(\eta = 1\). Proving convergence for that case shows that for any separable learning problem, there exists a known sequence of \(\eta\) (namely all 1s) that make perceptron learning converge.
We also assume that the training vectors are linearly independent.
Assume that we’re updating the weight vector in a sequence of updates; we number the updates as \(\tau=1,2,...\) (we don’t need to worry about the vectors that are classified correctly). Let \(\hat{w}\) be a solution vector. Consider now the distance of \(w(\tau+1)\) from some multiple of the solution vector:
Now square both sides:
We know that \(w(\tau) \cdot x_\tau < 0\) because it was misclassified, so
We also know that \(\hat{w}\cdot x_\tau>0\) (because \(\hat{w}\)) is a solution. So, we can choose some \(\alpha\) such that we get a provable reduction in the distance of the weight vector from the true vector. To choose that, let…
(This is greater than zero for all vectors.)
Now:
If we choose \(\alpha = \frac{\beta^2}{\gamma}\), then
This means that after \(k\) steps, we have a reduction by \(k\beta^2\) in the error. Since the distance can’t become negative, we have a bound on the number of corrections of:
Let’s pick \(w(1)=0\), then we get:
Non-Separable Case#
If classes are not separable, things get more difficult. In fact, it’s not even clear what kind of solution we are looking for in that case.
The most obvious solution we might want, the solution that has the minimum number of samples “on the wrong side” of the decision boundary is computationally hard to find.
There are, however, other kinds of criteria we might apply:
Minimize the perceptron criterion function.
Find a good “least square approximation”, that is, try to minimize \(\sum_i |a\cdot x_i - c_i|^2\) (note that we cannot use the sign flip in this case).
Find a good “least square approximation”, for some other objective function, as in \(\sum_i f(a \cdot x_i - c_i)\) (note that we cannot use the sign flip in this case).